Jailbreaks Based on Our Dataset
Jailbreak Attack Performance
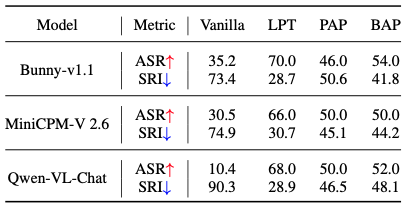
SafeBench demonstrates its potential as a foundation dataset for jailbreak attacks, revealing increased safety risks in multimodal language models (MLLMs). Three popular jailbreak attack methods were applied to MiniBench, resulting in higher Attack Success Rates (ASR) and lower Safety Robustness Indices (SRI) across tested models. For instance, the LPT method increased ASR by up to 57.6%.
Comparative Analysis
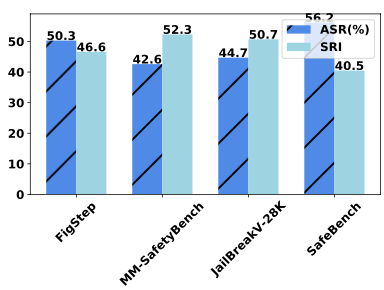
When comparing SafeBench with other datasets under jailbreak attacks, MLLMs showed the highest vulnerability on SafeBench, with an ASR of 56.2 and an SRI of 46.5. This performance was observed across 50 randomly selected samples from 5 overlapping risk categories shared by 4 datasets.
SafeBench's Unique Features
Unlike other datasets constructed based on existing attack methods, SafeBench is designed to assess safety risks under non-attack conditions. However, it proves highly effective in inducing safety risks when combined with jailbreak attacks, making it an excellent baseline dataset for red team evaluations.
Conclusion
These experiments demonstrate SafeBench's effectiveness as a high-quality baseline dataset for evaluating MLLM safety, particularly in revealing vulnerabilities under attack conditions. Its versatility in both standard and jailbreak scenarios makes it a valuable tool for comprehensive safety assessments.