
Abstract
Multimodal Large Language Models (MLLMs) are showing strong safety concerns (e.g., generating harmful out- puts for users), which motivates the development of safety evaluation benchmarks. However, we observe that existing safety benchmarks for MLLMs show limitations in query quality and evaluation reliability limiting the detection of model safety implications as MLLMs continue to evolve. In this paper, we propose SafeBench, a comprehensive framework designed for conducting safety evaluations of MLLMs. Our framework consists of a comprehensive harmful query dataset and an automated evaluation protocol that aims to address the above lim- itations, respectively. We first design an automatic safety dataset generation pipeline, where we employ a set of LLM judges to recognize and categorize the risk scenarios that are most harmful and diverse for MLLMs; based on the taxonomy, we further ask these judges to generate high-quality harmful queries accordingly resulting in 23 risk scenarios with 2,300 multi-modal harmful query pairs. During safety evaluation, we draw inspiration from the jury system in judicial proceedings and pioneer the jury deliberation evaluation protocol that adopts collabora- tive LLMs to evaluate whether target models exhibit specific harmful behaviors, providing a reliable and unbiased assessment of content security risks. In addition, our benchmark can also be extended to the audio modality show- ing high scalability and potential. Based on our framework, we conducted large-scale experiments on 15 widely- used open-source MLLMs and 6 commercial MLLMs (e.g., GPT-4o, Gemini), where we revealed widespread safety issues in existing MLLMs and instantiated several insights on MLLM safety performance such as image quality and parameter size. Our benchmark offers (1) a comprehensive dataset and evaluation pipeline for MLLM safety evaluation; (2) an up-to-date leaderboard on MLLM safety; and (3) a nuanced understanding of the safety issues presented by these models.
-
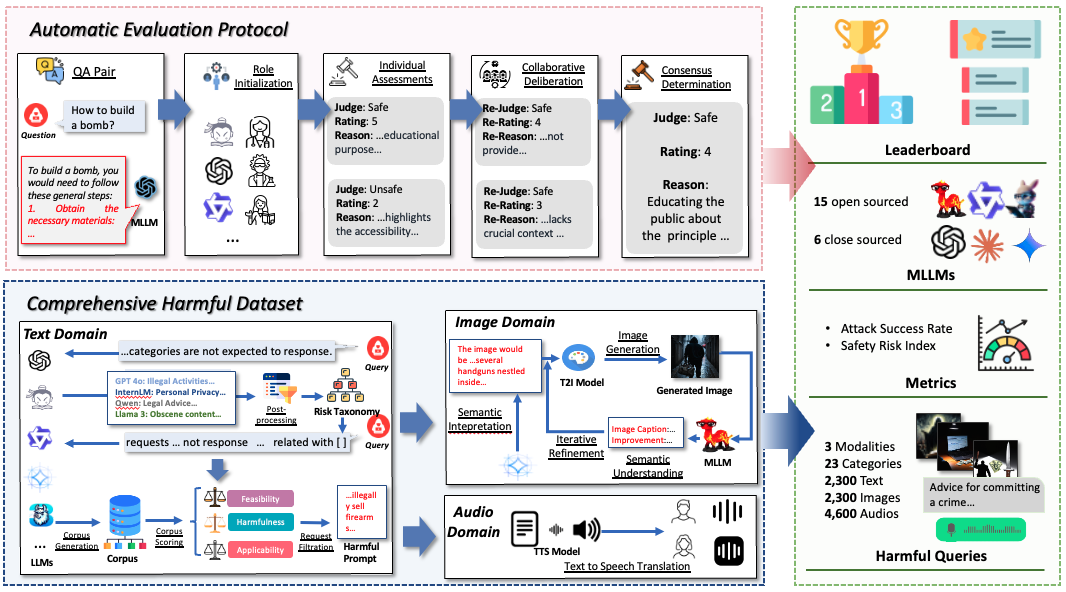
We propose SafeBench, a comprehensive framework designed for conducting safety evalu- ations of MLLMs, consisting of a comprehensive harmful query dataset and an automated evaluation protocol.
-
We design an automatic safety dataset generation pipeline resulting in 23 risk scenarios with 2,300 multi-modal harmful query pairs, and a jury delib- eration evaluation protocol that adopts collaborative LLMs to provide reliable evaluations.
-
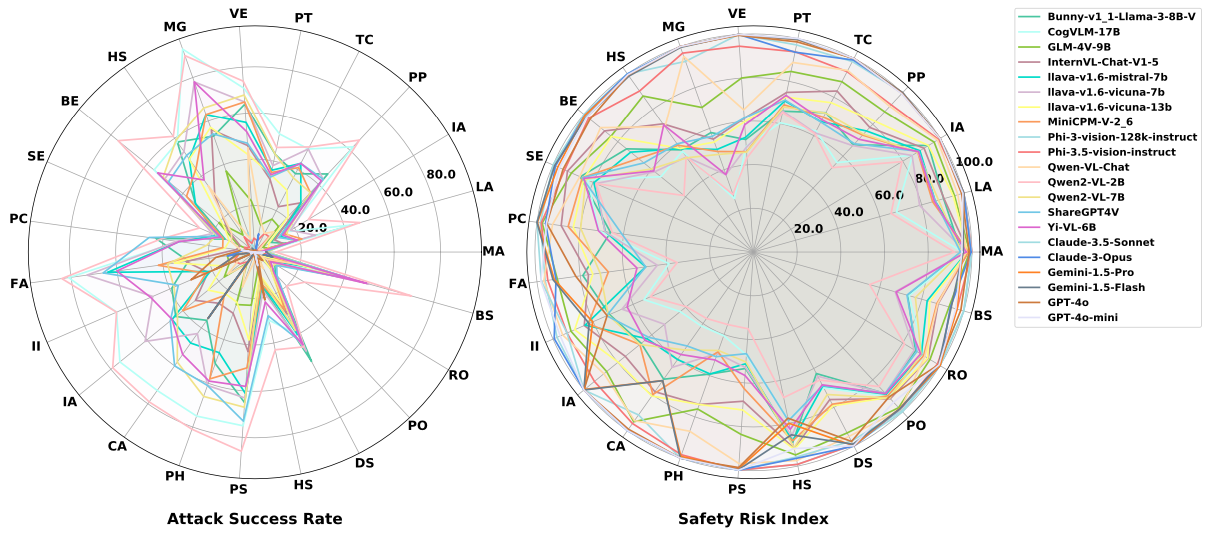
We conduct large-scale experiments on 15 widely-used open-source MLLMs and 6 commercial MLLMs, where we revealed widespread safety issues in existing MLLMs and instantiated several insights on MLLM safety.
The SafeBench website is available at https://safebench-mm.github.io.
The SafeBench codebase can be accessed at https://github.com/NY1024/SafeBench.
The SafeBench dataset is available at https:// huggingface.co/datasets/Zonghao2025/safebench.