Impact of Voice Modes and Multimodal Inputs on Language-Audio Models (LAMs)
Voice Mode Effects
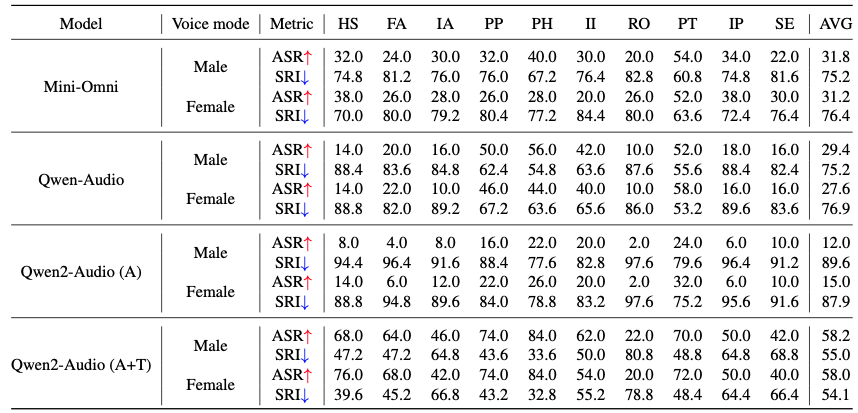
The data presented in the table reveals that voice mode variations have negligible effects on Language-Audio Models (LAMs), with the Attack Success Rate (ASR) difference between female and male voices remaining below 2% across all LAMs tested.
Qwen Series Comparison
A comparison of two generations within the Qwen series yields interesting insights. When restricted to audio input only, Qwen2-Audio (A) exhibits markedly enhanced safety performance compared to its predecessor, Qwen-Audio. Specifically, Qwen2-Audio achieves an average SRI that surpasses Qwen-Audio by 12.74 points.
Multimodal Input Vulnerability
However, a significant vulnerability emerges when both text and audio inputs are utilized (Qwen2-Audio (A+T)). In this multimodal scenario, Qwen2-Audio's safety performance deteriorates dramatically, recording its lowest average SRI of 54.52 and an elevated average ASR of 58.1%.
Conclusion and Future Research
These findings strongly suggest that the introduction of multimodal inputs introduces considerable safety risks to LAMs. This phenomenon warrants further investigation in future research to better understand and mitigate these vulnerabilities.